Ms sql server функции работы со строками. Строковые функции SQL. Символьные функции в языке sql
Здравствуйте, уважаемые читатели блога сайт. Сегодня я хотел бы поговорить о языке SQL, а в частности о функциях для обработки текста. Для создания и управления сайтом часто бывает не обязательно знание языка SQL. Системы управления контентом позволяют редактировать контент сайта без написания запросов. Но хотя бы поверхностное знакомство с структурированным языком запросов поможет вам значительно ускорить модификацию и управление данными в базе данных вашего сайта.
Передо мной частенько возникают задачи: удалить часть текста из текстовых полей базы данных, объединить строковые данные или еще что-нибудь связанное с текстом. Делать все это через админские панели сайтов очень неудобно и муторно. Гораздо проще бывает написать запрос к базе данных выполняющий все эти действия за пару секунд.
Итак, начнем...
Символьные функции в языке sql
Начнем по порядку с самого простого. Первой рассмотрим строковую функцию ASCII, которая используется для определения ASCII-кода текстовых символов:
integer ASCII (str string )
Функция возвращает целое значение — ASCII-код первого левого символа строки str. В случае если строка str пустая возвращает 0 и NULL если строка str не существует.
SELECT ASCII ("t");
Результат: 116
SELECT ASCII ("test");
Результат: 116
SELECT ASCII (1);
Результат: 49
integer ORD (str string )
Если первый левый символ строки str многобайтовый, то возвращает его код в формате: ((первый байт ASCII- код)*256+(второй байт ASCII -код))[*256+третий байт ASCII -код...]. В случае если первый левый символ строки str не является многобайтовым, работает как функция ASCII — возвращает его ASCII-код.
SELECT ORD ("test");
Результат: 116
Функция CHAR, тесно связанная с функцией ASCII и выполняет обратное действие:
string CHAR (int integer , ...)
Функция CHAR возвращает строку символов по их ASCII-кодам. Если среди значений встречается значение NULL, то оно пропускается.
SELECT CHAR (116, "101", 115, "116");
Результат: "test"
SQL функции для объединения строк
Одна из самых популярных категорий функций. Ведь частенько бывает нужно объединить значения нескольких полей таблиц базы данных сайта. В языке SQL есть сразу несколько функций для конкатенации строк .
Функция CONCAT:
string CONCAT (str1 string , str2 string ,...)
Функция возвращает строку, созданную путем объединения аргументов. Можно указывать более двух аргументов. Если один из аргументов является NULL, то и возвращаемый результат будет NULL. Числовые значения преобразуются в строку.
SELECT CONCAT ("Hello", " ", "world", "!");
Результат: "Hello world!"
SELECT CONCAT ("Hello", NULL, "world", "!");
Результат: NULL
SELECT CONCAT ("Число пи", "=", 3.14);
Результат: "Число пи=3.14"
Как видно из примеров, строки объединяются без разделителей. Для того чтобы разделить слова в первом примере в качестве аргумента приходится использовать пробел. Если бы слов было больше, то каждый раз вставлять пробелы было бы не очень удобно.
Для таких случаев существует функция CONCAT_WS:
string CONCAT_WS (separator string , str1 string , str2 string ,...)
Функция объединяет строки как и функция CONCAT, но вставляет между аргументами разделитель separator. В случае если аргумент separator является NULL, то и результат будет NULL. Аргументы строки равные NULL пропускаются.
SELECT CONCAT_WS (" ", "Иванов", "Иван", "Иванович");
Результат: "Иванов Иван Иванович"
SELECT CONCAT_WS (NULL, "Иванов", "Иван", "Иванович");
Результат: NULL
SELECT CONCAT_WS (" ", "Иванов", NULL, "Иван", "Иванович");
Результат: ""Иванов Иван Иванович"
В случае объединения большого количества строк, которые необходимо отделять разделителем, функция CONCAT_WS гораздо удобнее функции CONCAT.
Иногда бывает необходимо удлинить строку до определенного количества символов за счет повторения какого-либо символа. Это тоже своего рода объединение строк. Для этого можно использовать функции LPAD и RPAD . Функции имеют следующий синтаксис:
string
LPAD
(str string
, len integer
, padstr string
)
string
RPAD
(str string
, len integer
, padstr string
)
Функция LPAD возвращает строку str дополненную слева строкой padstr до длины len. Функция RPAD выполняет тоже самое, только удлинение происходит с правой стороны.
SELECT LPAD ("test", 10, ".");
Результат: ......test
SELECT RPAD ("test", 10, ".");
Результат: test......
В данных функциях необходимо обратить внимание на параметр len , который ограничивает количество выводимых символов. Поэтому если длина строки str будет больше чем параметр len, то строка будет обрезана:
SELECT LPAD ("test", 3, ".");
Результат: tes
Определение длины строки в sql запросах
Для определения количества символов в строке в языке SQL отвечает функция LENGTH — длина строки:
integer LENGTH (str string)
Функция возвращает целое число равное количеству символов в строке str.
SELECT LENGTH ("test");
Результат: 4
В случае использования многобайтовых кодировок функция LENGTH выдает не правильный результат. Например в случае если задана кодировка unicode, то запрос:
SELECT LENGTH ("тест");
вернет 8. Что, легко заметить, в два раза больше реального количества символов. В этом случае нужно использовать функцию CHAR_LENGTH:
integer CHAR_LENGTH (str string )
Функция также возвращает длину строки str и поддерживает многобайтовые символы .
Например:
SELECT CHAR_LENGTH ("тест");
Результат: 4
Поиск подстроки в строке средствами sql
Для вычисления позиции подстроки в строке в языке sql существует несколько функций. Первая, которую мы рассмотрим, функция POSITION:
integer POSITION (substr string IN str string )
Возвращает номер позиции первого вхождения подстроки substr в строке str и возвращает 0 если подстрока не найдена. Функция POSITION может работать с многобайтовыми символами.
SELECT POSITION ("cd" IN "abcdcde");
Результат: 3
SELECT POSITION ("xy" IN "abcdcde");
Результат: 0
Следующая функция LOCATE позволяет начинать поиск подстроки с определенной позиции:
integer LOCATE (substr string, str string , pos integer )
Возвращает позицию первого вхождения подстроки substr в строке str, начиная с позиции pos. Если параметр pos не задан, то поиск осуществляется с начала строки. Если подстрока substr не найдена, то возвращает 0. Поддерживает многобайтовые символы.
SELECT LOCATE ("cd", "abcdcdde", 5);
Результат: 5
SELECT LOCATE ("cd", "abcdcdde");
Результат: 3
Аналогом функций POSITION и LOCATE является функция INSTR:
integer INSTR (str string , substr string )
Также как и функции выше возвращает позицию первого вхождения подстроки substr в строке str. Единственное отличие от функций POSITION и LOCATE то, что аргументы поменяны местами.
Первыми рассмотрим сразу две функции LEFT и RIGHT, которые похожи по своему действию:
string
LEFT
(str string
, len integer
)
string
RIGHT
(str string
, len integer
)
Функция LEFT возвращает len первых символов из строки str, а функция RIGHT столько же последних. Поддерживают многобайтовые символы.
SELECT LEFT ("Москва", 3);
Результат: Мос
SELECT RIGHT ("Москва", 3);
Результат: ква
string
SUBSTRING
(str string
, pos integer
, len integer
)
string
MID
(str string
, pos integer
, len integer
)
Функции позволяют получить подстроку строки str длиною len символов с позиции pos. В случае если параметр len не задан, то возвращается вся подстрока начиная с позиции pos.
SELECT SUBSTRING ("г. Москва — столица России", 4, 6);
Результат: Москва
SELECT SUBSTRING ("г. Москва — столица России", 4);
Результат: Москва — столица России
Примеры с функцией MID не привожу, потому что результаты будут аналогичные.
Интересная функция SUBSTRING_INDEX:
string SUBSTRING_INDEX (str string , delim string , count integer )
Функция возвращает подстроку строки str, полученную путем удаления символов, идущих после разделителя delim, находящимся в позиции count. Параметр count может быть как положительным, так отрицательным. Если count положительный, то отсчет позиции разделителя будет вестись слева и удаляться будут символы находящиеся справа от разделителя. Если count отрицательный, то отсчет позиции разделителя ведется справа и удаляются символы находящиеся слева от разделителя. Возможно, описание получилось слишком запутанным, но на примерах станет понятней.
SELECT SUBSTRING_INDEX ("www.mysql.ru", ".", 1);
Результат: www
В данном примере функция находит, первое вхождения символа точки в строке «www.mysql.ru» и удаляет все символы, идущие после нее, включая сам разделитель.
SELECT SUBSTRING_INDEX ("www.mysql.ru", ".", 2);
Результат: www.mysql
Здесь функция ищет второе вхождение точки, удаляет все символы справа от нее и возвращает получившуюся подстроку. И еще один пример с отрицательным значением параметра count:
SELECT SUBSTRING_INDEX ("www.mysql.ru", ".", -2);
Результат: mysql.ru
В этом примере функция SUBSTRING_INDEX ищет вторую точку, отсчитывая позицию справа, удаляет символы слева от нее и выдает полученную подстроку.
Удаление пробелов из строки
Для удаления лишних пробелов из начала и конца строки в языке SQL есть три функции.
Функция LTRIM:
string LTRIM (str string )
Удаляет с начала строки str пробелы и возвращает результат.
Функция RTRIM:
string RTRIM (str string )
Также удаляет пробелы из строки str, только с конца. Обе функции поддерживают многобайтовые символы.
SELECT LTRIM (" текст ");
Результат: "текст "
SELECT RTRIM (" текст ");
Результат: " текст"
И третья функция TRIM позволяет сразу удалять пробелы из начала и из конца строки:
string TRIM ([ string FROM] str string )
Параметр str обязательный, остальные параметры не обязательные. В случае если задан только один параметр str, то возвращает строку str удалив пробелы из начала и конца строки одновременно.
SELECT TRIM (" текст ");
Результат: "текст"
С помощью пара метра remstr можно задавать символы или подстроки, которые будут удаляться из начала и конца строки. С помощью управляющих параметров BOTH, LEADING, TRAILING можно задавать откуда будут удаляться символы:
- BOTH — удаляет подстроку remstr с начала и с конца строки;
- LEADING — удаляет remstr с начала строки;
- TRAILING — удаляет remstr с конца строки.
SELECT TRIM (BOTH "а" FROM "текст");
Результат: "текст"
SELECT TRIM (LEADING "а" FROM "текстааа");
Результат: "текстааа"
SELECT TRIM (TRAILING "а" FROM "ааатекст");
Результат: "ааатекст"
Функция SPACE позволяет получить строку состоящую из определенного количества пробелов:
string SPACE (n integer )
Возвращает строку, которая состоит из n пробелов.
Функция REPLACE нужна для замены заданных символов в строке :
string REPLACE (str string , from_str string , to_str string )
Функция заменяет в строке str все подстроки from_str на to_str и возвращает результат. Поддерживает многобайтные символы.
SELECT REPLACE ("замена подстроки", "подстроки", "текста")
Результат: "замена текста"
Функция REPEAT:
string REPEAT (str string , count integer )
Функция возвращает строку, которая состоит из count повторений строки str. Поддерживает многобайтовые символы.
SELECT REPEAT ("w", 3);
Результат: "www"
Функция REVERSE переворачивает строку:
string REVERSE (str string )
Переставляет в строке str все символы с последнего на первый и возвращает результат. Поддерживает многобайтовые символы.
SELECT REVERSE ("текст");
Результат: "тскет"
Функция INSERT для вставки подстроки в строку:
string INSERT (str string , pos integer , len integer , newstr string )
Возвращает строку полученную в результате вставки в строку str подстроки newstr с позиции pos. Параметр len указывает сколько символов будет удалено из строки str, начиная с позиции pos. Поддерживает многобайтовые символы.
SELECT INSERT ("text", 2, 5, "MySQL");
Результат: "tMySQL"
"SELECT INSERT ("text", 2, 0, "MySQL");
Результат: "tMySQLext"
SELECT INSERT ("вставка текста", 2, 7, "MySQL");
Результат: "SELECT INSERT ("вставка текста", 2, 7, "MySQL");"
Если вдруг понадобиться заеменить в тексте все заглавные буквы на прописные, то можно воспользоваться одной из двух функций:
string LCASE (str string ) и string LOWER (str string )
Обе функции заменяют в строке str заглавные буквы на прописные и возвращают результат. И та и другая поддерживают многобайтовые символы.
SELCET LOWER ("АБВГДеЖЗиКЛ");
Результат:"абвгдежзикл"
Если же наоборот необходимо прописные буквы заменить заглавными, то также можно применить одну из двух функцийй:
string UCASE (str string ) и string UPPER (str string )
Функции возвращают строку str, заменив все прописные символы на заглавные. Также поддерживают многобайтовые символы.
Пример:
SELECT UPPER ("Абвгдежз");
Результат: "АБВГДЕЖЗ"
Строковых функций в языке SQL немного больше, чем рассмотрено в данной статье. Но так как даже большинство рассмотренных здесь функций используются редко, я закончу их рассмотрение. В следующих статьях я постараюсь рассмотреть реальные практические примеры использования строковых функций SQL. Поэтому не забудьте подписаться на обновления блога . До новых встреч!
В другие. Она имеет следующий синтаксис:
CONV(число,N,M)
Аргумент число находится в системе счисления с основанием N. Функция переводит его в систему счисления с основанием M и возвращает значение в виде строки.
Пример 1
Следующий запрос переводит число 2 из десятичной системы счисления в двоичную:
SELECT CONV(2,10,2);
Результат: 10
Для перевода числа 2E из шестнадцатиричной системы в десятичную требуется запрос:
SELECT CONV("2E",16,10);
Результат: 46
Функция CHAR() переводит ASCII-код в строки. Она имеет следующий синтаксис:
CHAR(n1,n2,n3..)
Пример 2
SELECT CHAR(83,81,76);
Результат: SQL
Следующие функции возвращают длину строки:
- LENGTH(строка);
- OCTET_LENGTH(строка);
- CHAR_LENGTH(строка);
- CHARACTER_LENGTH(строка).
Пример 3
SELECT LENGTH("MySQL");
Результат: 5
Иногда бывает полезной функция BIT_LENGTH(строка) , которая возвращает длину строки в битах.
Пример 4
SELECT BIT_LENGTH("MySQL");
Результат: 40
Функции работы с подстроками
Подстрокой обычно называют часть строки. Часто требуется узнать позицию первого вхождения подстроки в строку. Эту задачу в MySQL решают три функции:
- LOCATE(подстрока, строка [,позиция]);
- POSITION(подстрока, строка);
- INSTR(строка, подстрока).
Если подстрока не содержится в строке, то все три функции возвращают значение 0. Функция INSTR() отличается от двух других порядком аргументов. Функция LOCATE() может содержать третий аргумент позиция , который позволяет искать подстроку в строке не с начала, а с указанной позиции.
Пример 5
SELECT LOCATE("Топаз", "открытое акционерное общество Топаз");
Результат: 31
SELECT POSITION("Топаз", "открытое акционерное общество Топаз");
Результат: 31
SELECT INSTR("открытое акционерное общество Топаз",’Топаз’);
Результат: 31
SELECT LOCATE("Топаз", " Завод Топаз и ООО Топаз", 9);
Результат: 20
SELECT LOCATE("Алмаз", "открытое акционерное общество Топаз");
Результат: 0
Функции LEFT(строка, N) и RIGHT(строка, N) возвращают соответственно крайние левые и крайние правые N символов в строке.
Пример 6
SELECT LEFT("СУБД MySQL", 4);
Результат: СУБД
SELECT RIGHT("СУБД MySQL", 5);
Результат: MySQL
Иногда требуется получить подстроку, которая начинается с некоторой заданной позиции. Для этого используются функции:
- SUBSTRING(строка, позиция, N);
- MID(строка, позиция, N).
Обе функции возвращают N символов заданной строки, расположенных начиная с указанной позиции.
Пример 7
SELECT SUBSTRING("СУБД MySQL - одна из самых популярных СУБД", 6,5);
Результат: MySQL
При работе с электронными адресами и адресами сайтов очень полезна функция SUBSTR_INDEX() . Функция имеет три аргумента:
SUBSTR_INDEX(строка, разделитель, N).
Аргумент N может быть положительным или отрицательным. Если он отрицательный, то функция находит N-ое вхождение разделителя, если считать справа. После чего возвращает подстроку, расположенную справа от найденного разделителя. Если N положительно, то функция находит N-ое вхождение разделителя слева и возвращает подстроку, расположенную слева от найденного разделителя.
Пример 8
SELECT SUBSTRING_INDEX("www.mysql.ru",".",2);
Результат: www.mysql
SELECT SUBSTRING_INDEX("www.mysql.ru",".",-2);
Результат: mysql.ru
Функция REPLACE(строка,подстрока1,подстрока2) позволяет заменить в строке все вхождения подстроки1 на подстроку2.
Строковые функции Sql
Эта группа функций позволяет манипулировать текстом. Строковых функций много, мы рассмотрим наиболее употребительные.- CONCAT(str1,str2...)
Возвращает строку, созданную путем объединения аргументов (аргументы указываются
в скобках - str1,str2...). Например, в нашей таблице Поставщики (vendors) есть столбец Город (city) и столбец Адрес (address).
Предположим, мы хотим, чтобы в результирующей таблице Адрес и Город указывались в одном столбце, т.е. мы хотим
объединить данные из двух столбцов в один. Для этого мы будем использовать строковую функцию CONCAT(), а в качестве
аргументов укажем названия объединяемых столбцов - city и address:
SELECT CONCAT(city, address) FROM vendors;

Обратите внимание, объединение произошло без разделения, что не очень читабельно. Давайте подправим наш запрос, чтобы между объединяемыми столбцами был пробел:
SELECT CONCAT(city, " ", address) FROM vendors;

Как видите, пробел считается тоже аргументом и указывается через запятую. Если объединяемых столбцов было бы больше, то указывать каждый раз пробелы было бы нерационально. В этом случае можно было бы использовать строковую функцию CONCAT_WS(разделитель, str1,str2...) , которая помещает разделитель между объединяемыми строками (разделитель указывается, как первый аргумент). Наш запрос тогда будет выглядеть так:
SELECT CONCAT_WS(" ", city, address) FROM vendors;
Результат внешне не изменился, но если бы мы объединяли 3 или 4 столбца, то код значительно бы сократился.
- INSERT(str, pos, len, new_str)
Возвращает строку str, в которой подстрока, начинающаяся
с позиции pos и имеющая длину len символов, заменена подстрокой new_str. Предположим, мы решили в столбце Адрес (address)
не отображать первые 3 символа (сокращения ул., пр., и т.д.), тогда мы заменим их на пробелы:
SELECT INSERT(address, 1, 3, " ") FROM vendors;

То есть три символа, начиная с первого, заменены тремя пробелами.
- LPAD(str, len, dop_str)
Возвращает строку str, дополненную слева строкой dop_str до длины len.
Предположим, мы хотим, чтобы при выводе городов поставщиков они располагались бы справа, а пустое пространство заполнялось бы
точками:
SELECT LPAD(city, 15, ".") FROM vendors;

- RPAD(str, len, dop_str)
Возвращает строку str, дополненную справа строкой dop_str до длины len.
Предположим, мы хотим, чтобы при выводе городов поставщиков они располагались бы слева, а пустое пространство заполнялось бы
точками:
SELECT RPAD(city, 15, ".") FROM vendors;

Обратите внимание, значение len ограничивает количество выводимых символов, т.е. если название города будет длиннее 15 символов, то оно будет обрезано.
- LTRIM(str)
Возвращает строку str, в которой удалены все начальные пробелы. Эта строковая
функция удобна для корректного отображения информации в случаях, когда при вводе данных допускаются случайные пробелы:
SELECT LTRIM(city) FROM vendors;
- RTRIM(str)
Возвращает строку str, в которой удалены все конечные пробелы:
SELECT RTRIM(city) FROM vendors;
В нашем случае лишних пробелов не было, поэтому и результат внешне мы не увидим.
- TRIM(str)
Возвращает строку str, в которой удалены все начальные и конечные пробелы:
SELECT TRIM(city) FROM vendors;
- LOWER(str)
Возвращает строку str, в которой все символы переведены в нижний регистр.
С русскими буквами работает некорректно, поэтому лучше не применять. Например, давайте
применим эту функцию к столбцу city:
SELECT city, LOWER(city) FROM vendors;
 Видите, какая абракадабра получилась. А вот с латиницей все в порядке:
Видите, какая абракадабра получилась. А вот с латиницей все в порядке:
SELECT LOWER("CITY");

- UPPER(str)
Возвращает строку str, в которой все символы переведены в верхний регистр.
С русскими буквами так же лучше не применять. А вот с латиницей все в порядке:
SELECT UPPER(email) FROM customers;

- LENGTH(str)
Возвращает длину строки str. Например, давайте узнаем сколько символов в наших
адресах поставщиков:
SELECT address, LENGTH(address) FROM vendors;

- LEFT(str, len)
Возвращает len левых символов строки str. Например, пусть в городах поставщиков
выводится только первые три символа:
SELECT name, LEFT(city, 3) FROM vendors;

- RIGHT(str, len)
Возвращает len правых символов строки str. Например, пусть в городах поставщиков
выводится только последние три символа:
SELECT LOAD_FILE("C:/proverka");
 Обратите внимание, необходимо указывать абсолютный путь к файлу .
Обратите внимание, необходимо указывать абсолютный путь к файлу .
Сегодня предлагаю рассмотреть простые примеры использования строковых функций Transact-SQL , и не просто описание и примеры некоторых функций, а их сочетание, т.е. как можно вкладывать их друг в друга, так как для реализации многих задач стандартных функций бывает недостаточно и приходится их использовать совместно. И поэтому мне хотелось бы показать Вам пару простых примеров написания таких запросов.
Мы с Вами уже рассматривали строковые функции SQL , но так как реализации данного языка в разных СУБД различны, например некоторых функций нет в Transact-SQL, а в PL/PGSql они есть, и как раз в прошлый раз мы рассматривали строковые функции, которые можно использовать в plpgsql и поэтому сегодня мы поговорим именно о Transact-SQL.
Как можно сочетать SUBSTRING, CHARINDEX и LEN
И так, к примеру, Вам необходимо искать в строке ее часть по определенному критерию и вырезать ее, и не просто искать однотипную часть, а динамически, т.е. для каждой строки строка поиска будет разная. Примеры будем писать в Management Studio SQL Server 2008.
Для этого мы будем использовать следующие функции:
- SUBSTRING (str, start, len) – данная функция вырезает часть строки из другой строки. Имеет три параметра 1. Это сама строка; 2. Начальная позиция, с какой необходимо начать вырезать; 3. Количество символов, сколько необходимо вырезать.
- CHARINDEX (str1, str2)- ищет str1 в str2 и возвращает порядковый номер первого символа в случае нахождения такой строки. Имеет третий не обязательный параметр, с помощью которого можно указать с какой стороны начинать поиск.
- LEN (str1)-длина строки, т.е. количество символов.
Как Вы видите, здесь я использовал объявление переменных, а Вы вместо переменных можете подставлять свои поля в запросе. Вот сам код:
Declare @rezult as varchar(10) --исходная строка declare @str1 as varchar(100) --строка поиска declare @str2 as varchar(10) set @str1 = "Пробная строка string для поиска в ней другой строки" set @str2 = "string" set @rezult=substring(@str1,CHARINDEX(@str2, @str1), LEN(@str2)) select @rezult
Смысл здесь вот в чем, мы, используя функцию len узнаем, сколько символов необходимо вырезать, а charindex задает ту позицию, с которой необходимо начинать вырезать, и соответственно substring выполняет саму выборку в строке.
Как можно сочетать LEFT, RIGHT и LEN
Допустим, что Вам необходимо получить первые несколько символов в строке или проверить эти первые символы в строке на наличие чего-либо, например, какой-то номер, а его длина естественно разная (пример естественно тестовый).
- Left (str, kol) – функции вырезает указанное количество символов с лева, имеет два параметра первой это строка а второй соответственно количество символов;
- Right (str, kol) — функции вырезает указанное количество символов с право, параметры те же самые.
Теперь будем использовать простые запросы к таблице
Для начала давайте создадим таблицу test_table:
CREATE TABLE ( IDENTITY(1,1) NOT NULL, (18, 0) NULL, (50) NULL, CONSTRAINT PRIMARY KEY CLUSTERED ( ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON ) ON GOЗаполним ее тестовыми данными и напишем вот такие запросы:

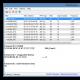
Как Вы понимаете первый запрос это просто выборка всех строк (Основы SQL — оператор select), а второй это уже непосредственно сочетание наших функций, вот код:
Select * from test_table select number, left(text,LEN(number)) as str from test_table
А если бы эти номера были справа, то мы бы использовали функцию RIGHT .
Использование Rtrim, Ltrim, Upper и Lower в сочетании
Допустив у Вас, есть строка с пробелами в начале и в конце, и Вы хотели бы, конечно же, от них избавиться и еще, например, сделать, так что первая буква в этой строке стала заглавной.
- Rtrim (str) –удаляет пробелы справа;
- Ltrim (str) – удаляет пробелы слева;
- Upper (str) – приводит строку в верхний регистр;
- Lower (str) — приводит строку в нижний регистр.

Как видите, для закрепления мы здесь использовали еще и Substring и Len . Смысл запроса прост, мы удаляем пробелы и справа и слева, затем приводим первый символ к верхнему регистру путем вырезания его, далее мы конкатенируем (оператор +) этот символ с оставшейся строкой. Вот код:
Declare @str1 as varchar(100) set @str1 = " тестовая строка с пробелами в начале и в конце " select @str1 select upper(substring(rtrim(ltrim(@str1)),1,1))+ lower(substring(rtrim(ltrim(@str1)),2,LEN(rtrim(ltrim(@str1)))-1))
На сегодня я думаю достаточно, и если Вам нравиться программировать на SQL то на этом сайте мы не раз затрагивали эту очень интересную тему, например.