Funkce serveru MS SQL pro práci s řetězci. Funkce SQL řetězců. Funkce znaků v jazyce SQL
Dobrý den, milí čtenáři tohoto blogu. Dnes bych chtěl mluvit o jazyce SQL a zejména o funkcích zpracování textu. K vytvoření a správě webu často není nutná znalost jazyka SQL. Redakční systémy umožňují upravovat obsah webových stránek bez psaní požadavků. Ale alespoň letmá znalost strukturovaného dotazovacího jazyka vám pomůže výrazně urychlit úpravy a správu dat v databázi vašeho webu.
Často čelím úkolům: odstranění části textu z textových polí databáze, sloučení řetězcových dat nebo čehokoli jiného, co souvisí s textem. Dělat to všechno prostřednictvím panelů správce webu je velmi nepohodlné a zdlouhavé. Je mnohem jednodušší napsat databázový dotaz, který provede všechny tyto akce během několika sekund.
Takže, začněme...
Funkce znaků v jazyce SQL
Začněme popořadě tím nejjednodušším. Nejprve se podívejme na funkci řetězce ASCII, která se používá k určení kódu ASCII textových znaků:
celé číslo ASCII(str tětiva)
Funkce vrací celočíselnou hodnotu – ASCII kód prvního levého znaku řetězce str. Pokud je řetězec str prázdný, vrátí 0 a NULL, pokud řetězec str neexistuje.
SELECT ASCII("t");
Výsledek: 116
SELECT ASCII("test");
Výsledek: 116
SELECT ASCII(1);
Výsledek: 49
celé číslo ORD(str tětiva)
Pokud je první levý znak řetězce str vícebajtový, vrátí svůj kód ve formátu: ((první bajt ASCII kód)*256+(druhý bajt ASCII kód))[*256+třetí bajt ASCII kód.. .]. Pokud první levý znak řetězce str není vícebajtový, funguje jako funkce ASCII a vrací svůj ASCII kód.
SELECT ORD("test");
Výsledek: 116
Funkce CHAR úzce souvisí s funkcí ASCII a dělá pravý opak:
tětiva CHAR(int celé číslo, ...)
Funkce CHAR vrací řetězec znaků na základě jejich kódů ASCII. Pokud je mezi hodnotami nalezena hodnota NULL, je přeskočena.
SELECT CHAR (116, "101", 115, "116");
Výsledek: "test"
SQL funkce pro zřetězení řetězců
Jedna z nejoblíbenějších kategorií funkcí. Koneckonců je často nutné kombinovat hodnoty několika polí v tabulkách databáze webu. Jazyk SQL má několik funkcí řetězení řetězců.
Funkce CONCAT:
tětiva CONCAT(str1 tětiva, str2 tětiva,...)
Funkce vrací řetězec vytvořený zřetězením argumentů. Můžete zadat více než dva argumenty. Pokud je jeden z argumentů NULL, bude vrácený výsledek NULL. Číselné hodnoty jsou převedeny na řetězec.
SELECT CONCAT("Ahoj", " ", "svět", "!");
Výsledek: "Ahoj světe!"
SELECT CONCAT("Ahoj", NULL, "svět", "!");
Výsledek: NULL
SELECT CONCAT("Pi", "=", 3,14);
Výsledek: "Pi=3,14"
Jak můžete vidět z příkladů, řetězce jsou zřetězeny bez oddělovačů. Chcete-li oddělit slova v prvním příkladu, musíte jako argument použít mezeru. Pokud by bylo slov více, pak by vkládání mezer pokaždé nebylo příliš pohodlné.
Pro takové případy existuje funkce CONCAT_WS:
tětiva CONCAT_WS(oddělovač tětiva, str1 tětiva, str2 tětiva,...)
Funkce zřetězí řetězce jako funkce CONCAT, ale mezi argumenty vloží oddělovač. Pokud je argument oddělovače NULL, bude výsledek NULL. Řetězcové argumenty rovné NULL jsou ignorovány.
SELECT CONCAT_WS (" ", "Ivanov", "Ivan", "Ivanovič");
Výsledek: "Ivanov Ivan Ivanovič"
SELECT CONCAT_WS (NULL, "Ivanov", "Ivan", "Ivanovich");
Výsledek: NULL
SELECT CONCAT_WS (" ", "Ivanov", NULL, "Ivan", "Ivanovič");
Výsledek: "Ivanov Ivan Ivanovič"
V případě sloučení velké množstvířádky, které je třeba oddělit oddělovačem, je funkce CONCAT_WS mnohem pohodlnější než funkce CONCAT.
Někdy je potřeba prodloužit řádek na určitý počet znaků opakováním znaku. Toto je také druh zřetězení řetězců. K tomu můžete použít funkce LPAD A RPAD. Funkce mají následující syntaxi:
tětiva LPAD(str tětiva len celé číslo,padstr tětiva)
tětiva RPAD(str tětiva len celé číslo,padstr tětiva)
Funkce LPAD vrátí řetězec vyplněný řetězcem padstr na délku len. Funkce RPAD dělá totéž, pouze rozšíření se vyskytuje na pravé straně.
SELECT LPAD("test", 10, ".");
Výsledek: ......test
SELECT RPAD("test", 10, ".");
Výsledek: test......
V těchto funkcích je třeba věnovat pozornost parametr len, což omezuje počet výstupních znaků. Pokud je tedy délka řetězce str větší než parametr len, bude řetězec zkrácen:
SELECT LPAD("test", 3, ".");
Výsledek: tes
Určení délky řetězce v dotazech SQL
Za určení počtu znaků v řetězci v jazyce SQL je zodpovědná funkce LENGTH - délka řetězce:
celé číslo DÉLKA(str tětiva)
Funkce vrátí celé číslo rovné počtu znaků v řetězci str.
SELECT LENGTH("test");
Výsledek: 4
Pokud je použito vícebajtové kódování, funkce LENGTH neposkytuje správný výsledek. Pokud je například kódování nastaveno na unicode, pak požadavek:
SELECT LENGTH("test");
vrátí 8. Což, jak je snadné vidět, je dvojnásobek skutečného počtu znaků. V tomto případě musíte použít funkci CHAR_LENGTH:
celé číslo CHAR_LENGTH(str tětiva)
Funkce se také vrátí délka čáry str a podporuje vícebajtové znaky.
Například:
SELECT CHAR_LENGTH("test");
Výsledek: 4
Hledání podřetězce v řetězci pomocí sql
Chcete-li vypočítat polohu podřetězce v řetězci v sql jazyk Existuje několik funkcí. První, na kterou se podíváme, je funkce POSITION:
celé čísloPOZICE(substr tětiva IN str tětiva)
Vrátí číslo pozice prvního výskytu podřetězce v řetězci str a vrátí 0, pokud podřetězec nebyl nalezen. Funkce POSITION může pracovat s vícebajtovými znaky.
SELECT POSITION("cd" IN "abcdcde");
Výsledek: 3
SELECT POSITION("xy" IN "abcdcde");
Výsledek: 0
Následující funkce LOCATE vám umožňuje začít hledat podřetězec na určité pozici:
celé číslo LOKALIZOVAT(substr tětiva, str tětiva,poz celé číslo)
Vrátí pozici prvního výskytu podřetězce v řetězci str, počínaje pozicí poz. Pokud není zadán parametr pos, pak se vyhledávání provádí od začátku řádku. Pokud podřetězec není nalezen, vrátí 0. Podporuje vícebajtové znaky.
SELECT LOCATE("cd", "abcdcdde", 5);
Výsledek: 5
SELECT LOCATE("cd", "abcdcdde");
Výsledek: 3
Analogem funkcí POSITION a LOCATE je funkce INSTR:
celé číslo INSTR(str tětiva,substr tětiva)
Stejně jako výše uvedené funkce vrací pozici prvního výskytu podřetězce v řetězci str. Jediný rozdíl od funkcí POSITION a LOCATE je v tom, že argumenty jsou prohozeny.
Nejprve se podívejme na dvě funkce LEFT a RIGHT, které jsou si podobné ve své činnosti:
tětiva VLEVO, ODJET(str tětiva len celé číslo)
tětiva ŽE JO(str tětiva len celé číslo)
Funkce LEFT vrací len prvních znaků z řetězce str a funkce RIGHT vrací stejné číslo posledního. Podporuje vícebajtové znaky.
SELECT LEFT("Moskva", 3);
Výsledek: Mos
SELECT RIGHT("Moskva", 3);
Výsledek: kwa
tětiva SUBSTRING(str tětiva,poz celé číslo len celé číslo)
tětiva STŘEDNÍ.(str tětiva,poz celé číslo len celé číslo)
Funkce umožňují získat podřetězec řetězce str s délkou znaků len z pozice pos. Pokud parametr len není zadán, vrátí se celý podřetězec počínaje pozicí poz.
SELECT SUBSTRING ("Moskva je hlavní město Ruska", 4, 6);
Výsledek: Moskva
SELECT SUBSTRING ("Moskva je hlavní město Ruska", 4);
Výsledek: Moskva je hlavním městem Ruska
Příklady s funkcí MID neuvádím, protože výsledky budou podobné.
Zajímavá funkce SUBSTRING_INDEX:
tětiva SUBSTRING_INDEX(str tětiva, delim tětiva, počet celé číslo)
Funkce vrací podřetězec řetězce str, získaný odstraněním znaků za oddělovačem delim, který se nachází na počtu pozic. Parametr počet může být kladný nebo záporný. Pokud je počet kladný, pozice oddělovače bude počítána zleva a znaky umístěné napravo od oddělovače budou vymazány. Pokud je počet záporný, pozice oddělovače se počítá zprava a znaky nalevo od oddělovače se odstraní. Možná se popis ukázal jako příliš matoucí, ale s příklady to bude jasnější.
SELECT SUBSTRING_INDEX ("www.mysql.ru", ".", 1);
Výsledek: www
V v tomto příkladu funkce najde první výskyt znaku tečky v řetězci „www.mysql.ru“ a odstraní všechny znaky, které za ním následují, včetně samotného oddělovače.
SELECT SUBSTRING_INDEX ("www.mysql.ru", ".", 2);
Výsledek: www.mysql
Zde funkce hledá druhý výskyt tečky, odstraní všechny znaky napravo od ní a vrátí výsledný podřetězec. A další příklad se zápornou hodnotou parametru count:
SELECT SUBSTRING_INDEX ("www.mysql.ru", ".", -2);
Výsledek: mysql.ru
V tomto příkladu funkce SUBSTRING_INDEX hledá druhý bod, počínaje zprava, odstraňuje znaky nalevo od něj a vrací výsledný podřetězec.
Odstranění mezer z řetězce
Pro odstranění prostory navíc od začátku a konce řetězce jsou v SQL tři funkce.
Funkce LTRIM:
tětiva LTRIM(str tětiva)
Odebere mezery ze začátku řetězce str a vrátí výsledek.
Funkce RTRIM:
tětiva RTRIM(str tětiva)
Také odstraní mezery z řetězce str, pouze z konce. Obě funkce podporují vícebajtové znaky.
SELECT LTRIM("text");
Výsledek: "text"
SELECT RTRIM("text");
Výsledek: "text"
A třetí funkce TRIM umožňuje okamžitě odstranit mezery ze začátku a konce řetězce:
tětiva TRIM([ tětiva OD] str tětiva)
Parametr str je povinný, ostatní parametry jsou volitelné. Pokud je zadán pouze jeden parametr str, vrátí řetězec str a současně odstraní mezery na začátku a na konci řetězce.
SELECT TRIM("text");
Výsledek: "text"
Parametr remstr umožňuje zadat znaky nebo podřetězce, které mají být odstraněny ze začátku a konce řetězce. Pomocí ovládacích parametrů BOTH, LEADING, TRAILING můžete určit, odkud budou znaky smazány:
- BOTH - odstraní podřetězec remstr ze začátku a konce řetězce;
- LEADING - odstraní remstr ze začátku řádku;
- TRAILING - odstraní remstr z konce řádku.
SELECT TRIM (OBA "a" Z "text");
Výsledek: "text"
SELECT TRIM (VEDENÍ "a" OD "textaa");
Výsledek: "textaaa"
SELECT TRIM (TRAILING "a" FROM "aaatext");
Výsledek: "aaatext"
Funkce SPACE umožňuje získat řetězec skládající se z určitého počtu mezer:
tětiva PROSTOR(n celé číslo)
Vrátí řetězec, který se skládá z n mezer.
Funkce REPLACE je potřebná pro nahrazení zadaných znaků v řetězci:
tětiva NAHRADIT(str tětiva, z_str tětiva, do_str tětiva)
Funkce nahradí všechny podřetězce from_str za to_str v řetězci str a vrátí výsledek. Podporuje vícebajtové znaky.
SELECT REPLACE ("náhrada podřetězce", "podřetězec", "text")
Výsledek: "náhrada textu"
Funkce REPEAT:
tětiva OPAKOVAT(str tětiva, počet celé číslo)
Funkce vrací řetězec, který se skládá z počtu opakování řetězce str. Podporuje vícebajtové znaky.
SELECT REPEAT("w", 3);
Výsledek: "www"
Funkce REVERSE obrátí řetězec:
tětiva ZVRÁTIT(str tětiva)
Přeuspořádá všechny znaky v řetězci str od posledního k prvnímu a vrátí výsledek. Podporuje vícebajtové znaky.
SELECT REVERSE("text");
Výsledek: "tsket"
Funkce INSERT pro vložení podřetězce do řetězce:
tětivaVLOŽIT(str tětiva,poz celé číslo len celé číslo, newsstr tětiva)
Vrátí řetězec získaný jako výsledek vložení podřetězce newstr do řetězce str z pozice poz. Parametr len udává, kolik znaků bude odstraněno z řetězce str, počínaje pozicí poz. Podporuje vícebajtové znaky.
SELECT INSERT("text", 2, 5, "MySQL");
Výsledek: "tMySQL"
"SELECT INSERT("text", 2, 0, "MySQL");
Výsledek: "tMySQLext"
SELECT INSERT ("vložit text", 2, 7, "MySQL");
Výsledek: "SELECT INSERT ("vložit text", 2, 7, "MySQL");"
Pokud náhle potřebujete nahradit všechna velká písmena v textu velkými písmeny, můžete použít jednu ze dvou funkcí:
tětiva LCASE(str tětiva) A tětiva DOLNÍ(str tětiva)
Obě funkce nahradí velká písmena v řetězci str velkými písmeny a vrátí výsledek. Oba podporují vícebajtové znaky.
SELCET LOWER("ABVGDeZhZiKL");
Výsledek: "abvgdezhzikl"
Pokud je naopak nutné nahradit velká písmena velkými písmeny, můžete také použít jednu ze dvou funkcí:
tětiva UCASE(str tětiva) A tětiva HORNÍ (str tětiva)
Funkce vrátí řetězec str a nahradí všechna velká písmena velkými písmeny. Podporuje také vícebajtové znaky.
Příklad:
SELECT UPPER("Abvgdezh");
Výsledek: "ABVGDEZHZ"
V SQL je o něco více řetězcových funkcí, než je popsáno v tomto článku. Ale protože i většina zde probíraných funkcí se používá zřídka, přestanu je rozebírat. V následujících článcích se pokusím podívat na reálné praktické příklady použití funkcí SQL string. Takže se nezapomeňte přihlásit k odběru aktualizací blogu. Uvidíme se znova!
Ostatním. Má následující syntaxi:
CONV(číslo;N;M)
Argument číslo je v základu N. Funkce jej převede na základ M a vrátí hodnotu jako řetězec.
Příklad 1
Následující dotaz převede číslo 2 z desítkové na binární:
SELECT CONV(2;10;2);
Výsledek: 10
Chcete-li převést číslo 2E z hexadecimálního na desítkové, je vyžadován následující dotaz:
SELECT CONV("2E",16;10);
Výsledek: 46
Funkce CHAR() převádí ASCII kód na řetězce. Má následující syntaxi:
CHAR(n1;n2;n3..)
Příklad 2
SELECT CHAR(83;81;76);
Výsledek: SQL
Následující funkce vrátí délku řetězce:
- DÉLKA(řetězec);
- OCTET_LENGTH(řetězec);
- CHAR_LENGTH(řetězec);
- CHARACTER_LENGTH(řetězec).
Příklad 3
SELECT LENGTH("MySQL");
Výsledek: 5
Občas se to stane užitečná funkce BIT_LENGTH(řetězec), který vrací délku řetězce v bitech.
Příklad 4
SELECT BIT_LENGTH("MySQL");
Výsledek: 40
Funkce pro práci s podřetězci
Podřetězec je obvykle součástí řetězce. Často potřebujete znát pozici prvního výskytu podřetězce v řetězci. Tento problém v MySQL řeší tři funkce:
- LOCATE(podřetězec, řetězec [,pozice]);
- POSITION(podřetězec, řetězec);
- INSTR(řetězec, podřetězec).
Pokud podřetězec není obsažen v řetězci, vrátí všechny tři funkce 0. Funkce INSTR() se od ostatních dvou liší v pořadí svých argumentů. Funkce LOCATE() může obsahovat třetí argument pozice, který umožňuje hledat podřetězec v řetězci nikoli od začátku, ale od zadané pozice.
Příklad 5
SELECT LOCATE("Topaz", "otevřená akciová společnost Topaz");
Výsledek: 31
SELECT POSITION("Topaz", "otevřená akciová společnost Topaz");
Výsledek: 31
SELECT INSTR("Otevřená akciová společnost Topaz", 'Topaz');
Výsledek: 31
SELECT LOCATE("Topaz", "Topaz Plant and Topaz LLC", 9);
Výsledek: 20
SELECT LOCATE("Almaz", "Otevřená akciová společnost Topaz");
Výsledek: 0
Funkce VLEVO(řádek; N) A RIGHT(řetězec; N) vrátí N znaků nejvíce vlevo a nejvíce vpravo v řetězci.
Příklad 6
SELECT LEFT("MySQL DBMS", 4);
Výsledek: DBMS
SELECT RIGHT("MySQL DBMS", 5);
Výsledek: MySQL
Někdy potřebujete získat podřetězec, který začíná na určité dané pozici. K tomu slouží následující funkce:
- PODŘETĚZEC(řetězec, pozice, N);
- MID(řádek, pozice, N).
Obě funkce vracejí N znaků daného řetězce počínaje zadanou pozicí.
Příklad 7
SELECT SUBSTRING("MySQL DBMS je jedním z nejpopulárnějších DBMS", 6.5);
Výsledek: MySQL
Při práci s emailová adresa a adresy webových stránek je velmi užitečná funkce SUBSTR_INDEX(). Funkce má tři argumenty:
SUBSTR_INDEX(řetězec, oddělovač, N).
Argument N může být kladný nebo záporný. Pokud je záporné, pak funkce najde N-tý výskyt oddělovače, počítá se zprava. Poté vrátí podřetězec umístěný napravo od nalezeného oddělovače. Pokud je N kladné, pak funkce najde N-tý výskyt oddělovače vlevo a vrátí podřetězec umístěný nalevo od nalezeného oddělovače.
Příklad 8
SELECT SUBSTRING_INDEX("www.mysql.ru",".,2);
Výsledek: www.mysql
SELECT SUBSTRING_INDEX("www.mysql.ru",".",-2);
Výsledek: mysql.ru
Funkce REPLACE(řetězec, dílčí řetězec1, dílčí řetězec2) umožňuje nahradit všechny výskyty podřetězec1 podřetězcem2 v řetězci.
Funkce řetězce SQL
Tato skupina funkcí umožňuje manipulovat s textem. Řetězcových funkcí je mnoho, my se podíváme na ty nejběžnější.- CONCAT(str1,str2...) Vrací řetězec vytvořený zřetězením argumentů (argumenty jsou v závorkách - str1,str2...). Například v naší tabulce Dodavatelé je sloupec Město a sloupec Adresa. Předpokládejme, že chceme, aby výsledná tabulka měla adresu a město ve stejném sloupci, tzn. chceme spojit data ze dvou sloupců do jednoho. K tomu použijeme řetězcovou funkci CONCAT() a jako argumenty uvedeme názvy sloupců, které mají být kombinovány – město a adresa:
SELECT CONCAT(město, adresa) FROM dodavatelů;

Upozorňujeme, že ke sloučení došlo bez rozdělení, což není příliš čitelné. Upravme náš dotaz tak, aby mezi spojovanými sloupci byla mezera:
SELECT CONCAT(město, " ", adresa) FROM dodavatelů;

Jak vidíte, mezera je také považována za argument a je označena oddělenou čárkou. Pokud by mělo být sloučeno více sloupců, bylo by pokaždé zadávat mezery iracionální. V tomto případě lze použít funkci string CONCAT_WS(oddělovač, str1,str2...), který umístí oddělovač mezi zřetězené řetězce (oddělovač je uveden jako první argument). Náš dotaz pak bude vypadat takto:
SELECT CONCAT_WS(" ", město, adresa) FROM dodavatelů;
Výsledek se externě nezměnil, ale pokud bychom spojili 3 nebo 4 sloupce, kód by se výrazně zkrátil.
- INSERT(str; pozice; délka; nový_str) Vrátí řetězec str s podřetězcem začínajícím na pozici pos a má délku znaků len nahrazenou podřetězcem nový_str. Předpokládejme, že se rozhodneme nezobrazovat první 3 znaky ve sloupci Adresa (zkratky st., pr. atd.), pak je nahradíme mezerami:
SELECT INSERT(adresa, 1, 3, " ") FROM dodavatelů;

To znamená, že tři znaky, počínaje prvním, jsou nahrazeny třemi mezerami.
- LPAD(str, len, dop_str) Vrací řetězec str, vlevo doplněný dop_str na délku len. Řekněme, že chceme zobrazit dodavatelská města vpravo a vyplnit prázdné místo tečkami:
SELECT LPAD(město, 15, ".") FROM dodavatelů;

- RPAD(str, len, dop_str) Vrací řetězec str, doplněný zprava dop_str na délku len. Řekněme, že chceme zobrazit města dodavatelů vlevo a vyplnit prázdné místo tečkami:
SELECT RPAD(město, 15, ".") FROM dodavatelů;

Upozorňujeme, že hodnota len omezuje počet zobrazených znaků, tzn. pokud je název města delší než 15 znaků, bude zkrácen.
- LTRIM(str) Vrací řetězec str s odstraněnými počátečními mezerami. Tato funkce řetězce je vhodná pro správné zobrazení informací v případech, kdy jsou při zadávání dat povoleny náhodné mezery:
SELECT LTRIM(město) FROM prodejců;
- RTRIM(str) Vrátí řetězec str s odstraněnými koncovými mezerami:
SELECT RTRIM(město) FROM dodavatelů;
V našem případě nebyly žádné mezery navíc, takže výsledek externě neuvidíme.
- TRIM(str) Vrátí řetězec str bez všech úvodních a koncových mezer:
SELECT TRIM(město) FROM prodejců;
- LOWER(str) Vrací řetězec str se všemi znaky převedenými na malá písmena. S ruskými písmeny to nefunguje správně, takže je lepší ho nepoužívat. Aplikujme například tuto funkci na sloupec města:
SELECT city, LOWER(city) FROM dodavatelů;
 Podívejte se, jaká se z toho vyklubala pitomost. Ale s latinskou abecedou je vše v pořádku:
Podívejte se, jaká se z toho vyklubala pitomost. Ale s latinskou abecedou je vše v pořádku: SELECT LOWER("MĚSTO");

- UPPER(str) Vrací řetězec str se všemi znaky převedenými na velká písmena. U ruských písmen je také lepší jej nepoužívat. Ale s latinskou abecedou je vše v pořádku:
SELECT UPPER(email) OD zákazníků;

- LENGTH(str) Vrací délku řetězce str. Pojďme například zjistit, kolik znaků je v adresách našich dodavatelů:
SELECT adresa, LENGTH(adresa) FROM dodavatelů;

- LEFT(str, len) Vrátí znaky len vlevo v řetězci str. Nechte například v dodavatelských městech zobrazovat pouze první tři znaky:
SELECT jméno, LEFT(město, 3) FROM dodavatelů;

- RIGHT(str, len) Vrací znaky len right řetězce str. Například v dodavatelských městech nechejte zobrazit pouze poslední tři znaky: SELECT LOAD_FILE("C:/proverka");
 Upozorňujeme, že musíte zadat absolutní cestu k souboru.
Upozorňujeme, že musíte zadat absolutní cestu k souboru.
Dnes navrhuji podívat se na jednoduché příklady použití tětiva Funkce Transact-SQL , a to nejen popis a příklady některých funkcí, ale jejich kombinace, tzn. jak je lze vnořit do sebe, protože k implementaci mnoha úloh standardní funkce nestačí a je třeba je používat společně. A proto bych vám rád pár ukázal jednoduché příklady psaní takových žádostí.
Už jsme se podívali na funkce SQL řetězců, ale od implementací tohoto jazyka Různé DBMS se liší, například některé funkce nejsou v Transact-SQL, ale jsou v PL/PGSql a minule jsme se podívali na řetězcové funkce, které lze použít v plpgsql, a proto si dnes povíme konkrétně o Transact- SQL.
Jak kombinovat SUBSTRING, CHARINDEX a LEN
A tak je třeba například hledat část řetězce podle určitého kritéria a vystřihnout ji a nehledat pouze část stejného typu, ale dynamicky, tzn. Vyhledávací řetězec se bude pro každý řetězec lišit. Příklady napíšeme v Managementu Studio SQL Server 2008.
K tomu použijeme následující funkce:
- SUBSTRING(str, start, len) – tuto funkci odstřihne část provázku z jiného provázku. Má tři parametry 1. Toto je samotný řetězec; 2. Výchozí pozice, ze které se má začít řezat; 3. Počet znaků, které je třeba oříznout.
- CHARINDEX(str1, str2) - vyhledá str1 v str2 a vrátí pořadové číslo prvního znaku, pokud je takový řetězec nalezen. Má třetí volitelný parametr, pomocí kterého můžete určit, ze které strany má vyhledávání začít.
- LEN(str1) - délka řetězce, tzn. Postavy.
Jak vidíte, zde jsem použil deklarace proměnných a místo proměnných můžete v požadavku nahradit vlastní pole. Zde je samotný kód:
Deklarujte @rezult jako varchar(10) --zdrojový řetězec deklarujte @str1 jako varchar(100) --hledaný řetězec deklarujte @str2 jako varchar(10) set @str1 = "Testovací řetězec pro hledání jiného řetězce v něm" set @str2 = "string" set @rezult=substring(@str1,CHARINDEX(@str2, @str1), LEN(@str2)) vybrat @rezult
Jde zde o toto: pomocí funkce len zjistíme, kolik znaků je potřeba oříznout, a charindex nastaví pozici, ze které musíme začít stříhat, a podle toho substring provede výběr sám v řetězci.
Jak kombinovat LEFT, RIGHT a LEN
Řekněme, že potřebujete získat prvních několik znaků v řetězci nebo zkontrolovat tyto první znaky v řetězci na přítomnost něčeho, například nějakého čísla, a jeho délka je přirozeně různá (příkladem je samozřejmě zkušební).
- Vlevo, odjet(str, kol) – funkce vyříznou zadaný počet znaků zleva, mají dva parametry, první je řetězec a druhý počet znaků;
- Že jo(str, kol) - funkce vyříznou zadaný počet znaků zprava, parametry jsou stejné.
Nyní použijeme jednoduché dotazy proti tabulce
Nejprve vytvořte tabulku test_table:
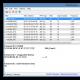
VYTVOŘIT TABULKU ( IDENTITY(1,1) NOT NULL, (18, 0) NULL, (50) NULL, OMEZENÍ PRIMÁRNÍCH KLÍČŮ SE SLUSTROVANÝM (ASC) S (PAD_INDEX = VYPNUTO, STATISTICS_NORECOMPUTE = VYPNUTO, IGNORE_DUP_KEYS = VYPNUTO, VYPNUTO, VYPNUTO = ON) ON ) ON GONaplňte jej testovacími daty a napište následující dotazy:

Jak jste pochopili, první dotaz je jednoduše výběr všech řádků (Základy SQL - příkaz select) a druhý je přímá kombinace našich funkcí, zde je kód:
Vyberte * z testovací_tabulky vyberte číslo, vlevo(text,DÉLKA(číslo)) jako str z testovací_tabulky
A pokud by tato čísla byla vpravo, pak bychom funkci použili ŽE JO.
Použití Rtrim, Ltrim, Upper a Lower v kombinaci
Řekněme, že máte řádek s mezerami na začátku a na konci a rádi byste se jich samozřejmě zbavili a například první písmeno v tomto řádku udělali velké.
- Rtrim(str) – odstraní mezery zprava;
- Ltrim(str) – odstraní mezery vlevo;
- Horní(str) – převede řetězec na velká písmena;
- Dolní(str) - převede řetězec na malá písmena.

Jak vidíte, k zabezpečení jsme zde také použili Podřetězec A Len. Význam požadavku je jednoduchý, odstraníme mezery vpravo i vlevo a poté převedeme první znak na velká písmena vyříznutím pak tento znak zřetězíme (operátor +) se zbývajícím řetězcem. Zde je kód:
Deklarujte @str1 jako varchar(100) set @str1 = " testovací řetězec s mezerami na začátku a na konci " select @str1 select upper(substring(rtrim(ltrim(@str1)),1,1))+ lower(substring( rtrim( ltrim(@str1)),2,LEN(rtrim(ltrim(@str1)))-1))
Pro dnešek to myslím stačí, a pokud rádi programujete v SQL, tak na tomto webu jsme se dotkli právě tohoto zajímavé téma, Například.